
1PE 视频学习
1.认识PE
首先,先介绍什么是**可执行文件(executable file)**:可以由操作系统进行加载执行的文件
而 PE(Portable Executable) 就是windows操作系统的可执行文件结构,一种可移植的可执行文件,即可在任何windows平台上运行
另外 ELF(Executable and Linking Format)是Linux系统的可执行文件结构
1.1PE文件格式的运用
- 病毒与反病毒
- 外挂与反外挂
- 加壳与脱壳
- 无源码修改功能、软件汉化。。。等
1.2如何识别PE文件
1.2.1 文件后缀名
一般的来说,DLL,EXE,OCX,SYS等这些都是可执行文件
但这种判断方式很片面,PE文件可以是任何拓展名,只要它这个文件符合PE文件结构,就能确定它是PE文件,所以这里可以根据它的文件结构来判断它是否是PE文件—PE指纹
1.2.2 PE指纹
使用2进制文本编辑软件查看,这里我是用的是WinHex,通过它打开文件,就可以看到文件的16进制值、对应的ascii码,还有偏移量。。。等等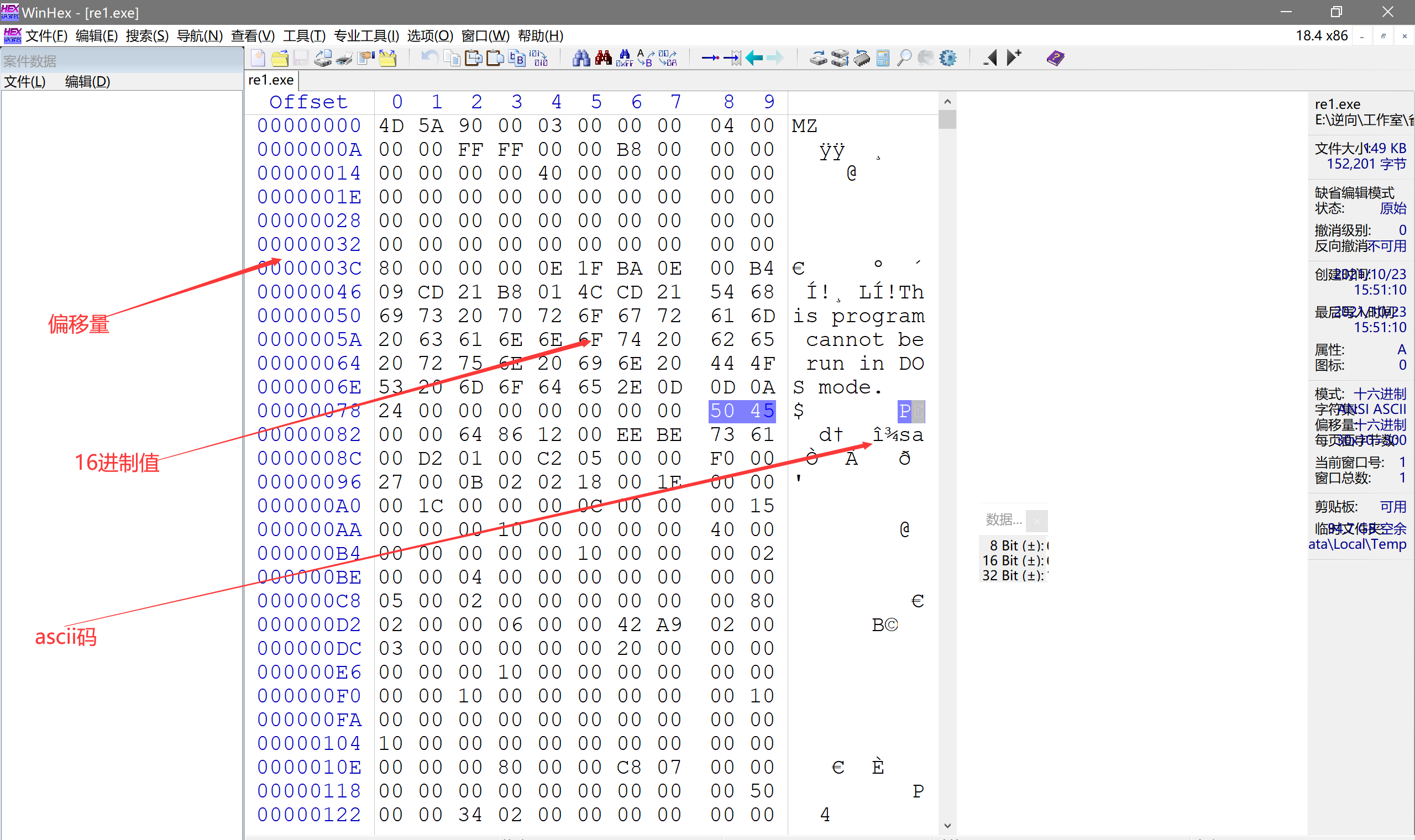
这里我打开的是一个exe文件,判断其文件是否是PE文件的步骤如下:
- 看头两个字节是否是 4D 5A ,对应的ascii码是“MZ”,然后看偏移量为3C的位置,上图为80,然后再找到偏移量为80的位置,看到16进制值“50 45” 对应的ascII是PE,这样就能判断其文件为PE文件了
1.3 PE文件的整体结构
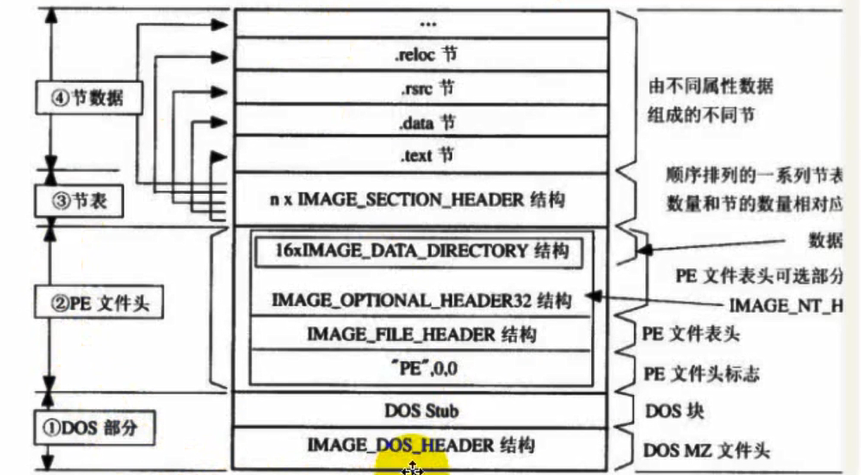
如上图,PE文件的整体结构由下到上分为:DOS部分、PE文件头、节表、节数据,其中前三个部分更像是“说明书”,由结构体组成,这些结构体可以在 WINNT.h 文件中找到。而节数据就像是一个文本里的内容,就是一些具体的数据。其中通过学习这些结构体,就是DOS部分、PE文件头和节表就能更清楚那些16进制所代表的是些什么,以及他们为什么要这样写。
1.4 认识PE文件在磁盘中的状态
1.4.1 DOS部分
在一个PE文件的第一部分就是一个结构体——IMAGE_DOS_HEADER,也被称为 DOS MZ文件头

1 | typedef struct _IMAGE_DOS_HEADER { |
该结构体大小为64个字节,所以对着二进制文件看,前64个字节长度的内容都是 DOS MZ文件头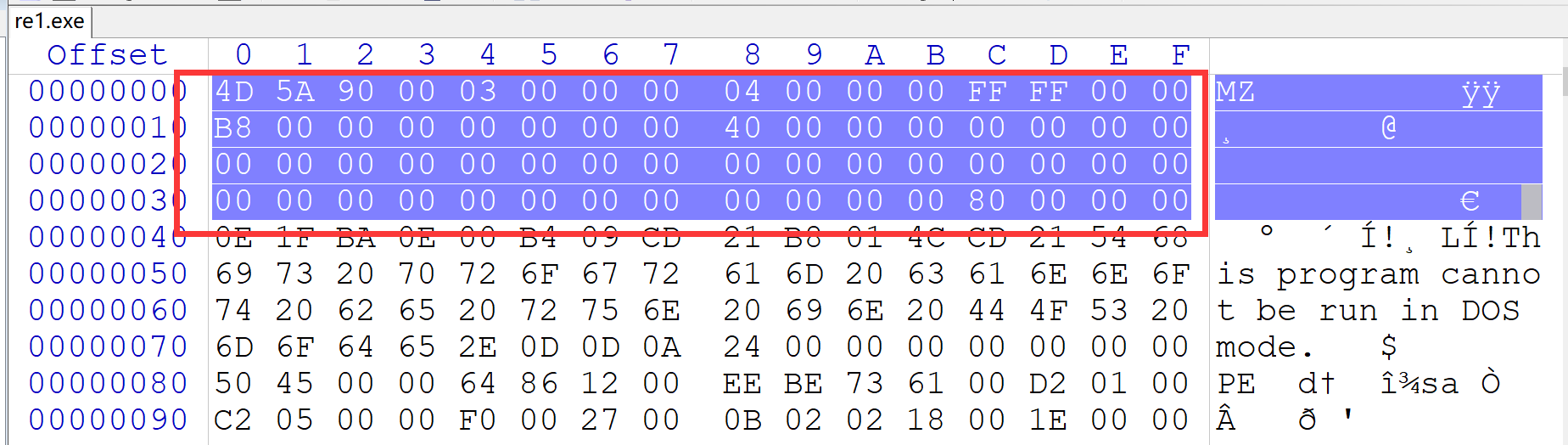
然后看结构体中的最后一个变量 LONG e_lfanew; 这是long型变量,4字节大小,同时这个变量指向PE文件头的位置,在上图指向的PE头就是 80 位置。
其次就是 DOS stub,DOS块,这部分的大小是不确定的,有连接器决定,同时这部分的内容是可修改的,并不会对PE文件的运行造成修改。虽然这部分的大小是不确定的,但是我们可以根据DOS MZ文件头和PE文件头来确定————PE文件头上面,DOS MZ文件头最后一个变量的后面。如下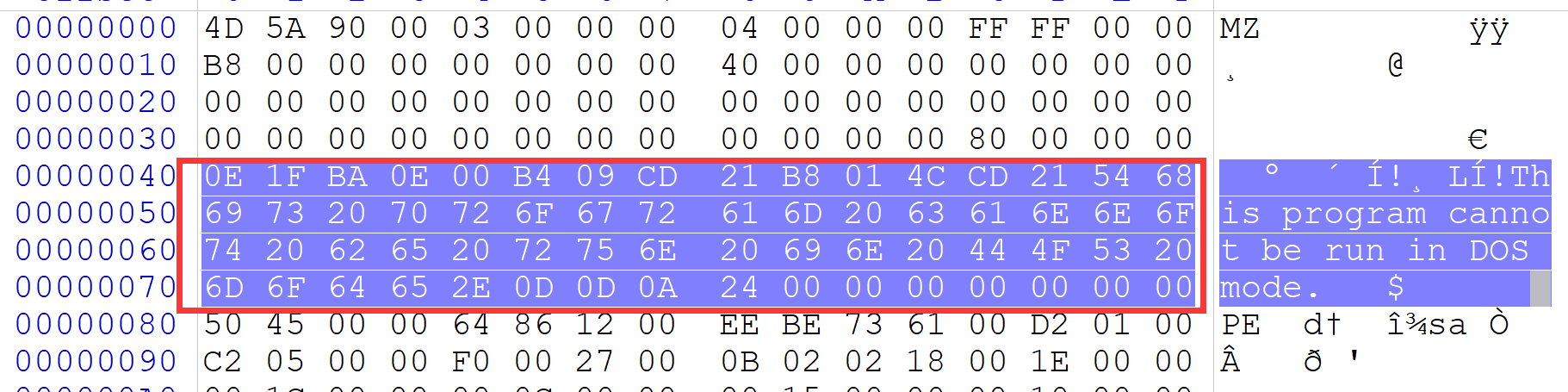
一般其16进制值对应的内容都是
1 | This program must be run under Win32 |
这就是PE文件 DOS部分的大概描述,这部分在现在的windows上大概都是无关紧要的,所以可以在这部分进行相关修改,例如将其全置0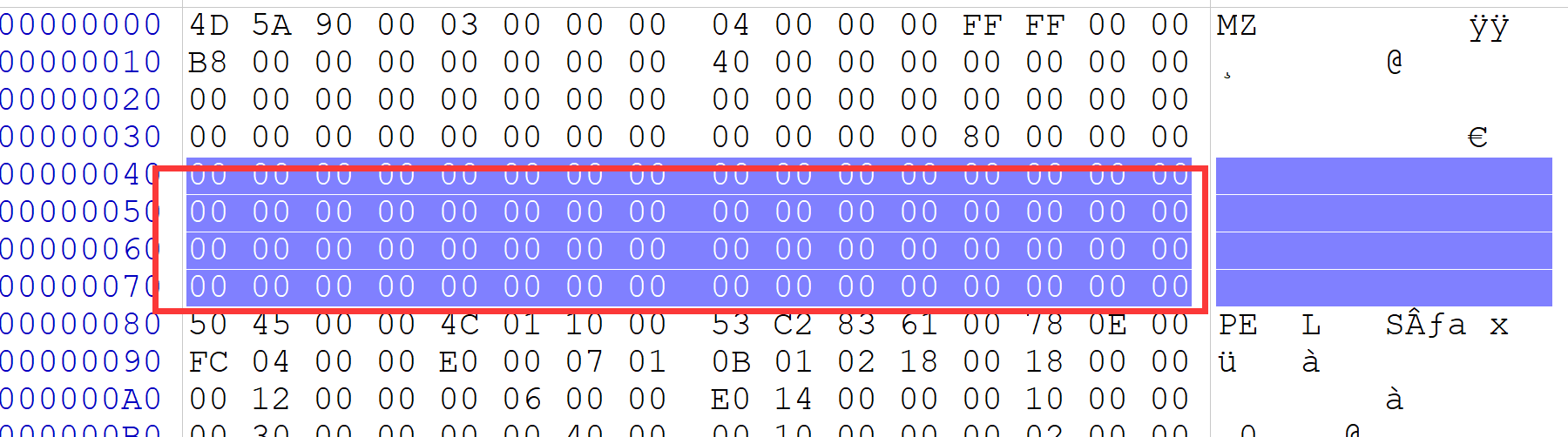
其修改前后运行结果一致。
1.4.2 PE文件头

由结构体 IMAGE_NT_HEADERS 组成
1 | typedef struct _IMAGE_NT_HEADERS { |
按其大小找到二进制文件中所指定的内容
首先是 PE文件头标志 就是DOS结构体最后一个变量指向的十六进制值 “50 45 00 00” 其ascii对应的就是 ”PE “
然后就是 标准PE头 ,20字节长度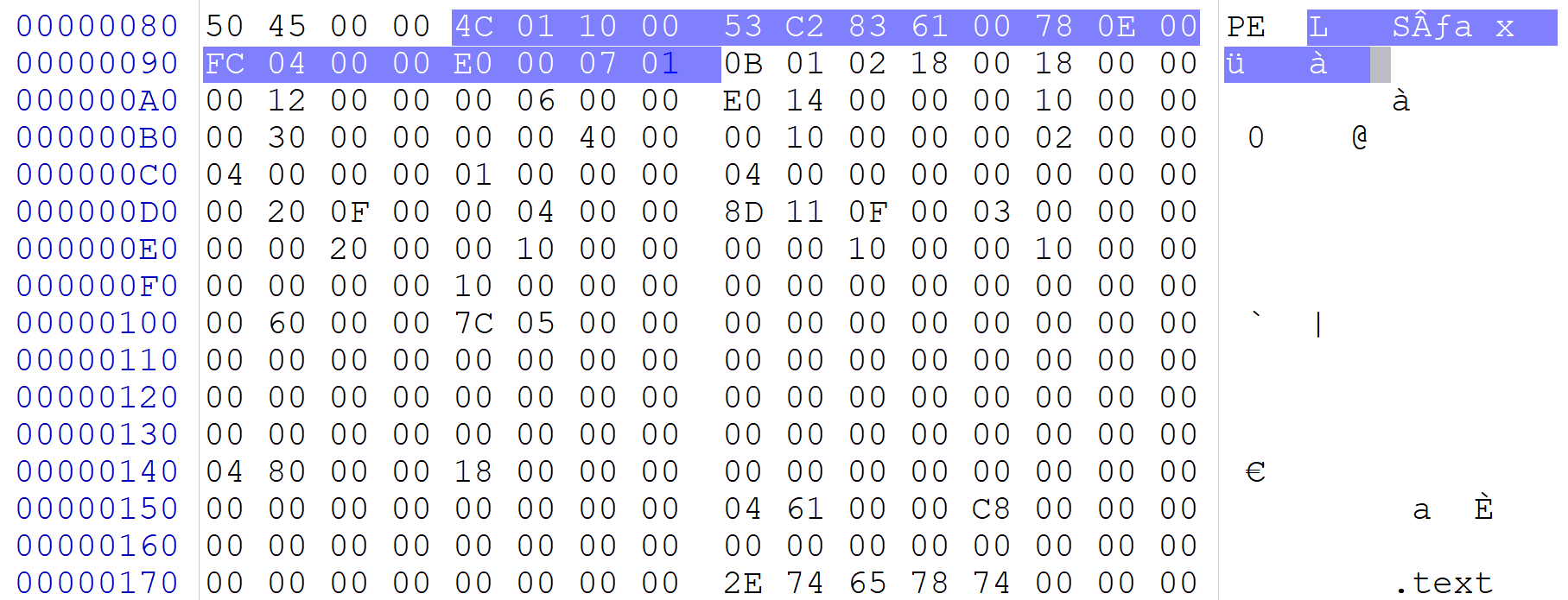
再就是 拓展PE头,其大小可由结构体 IMAGE_FILE_HEADER 中的成员SizeOfOptionalHeader 所指定
1 | //标准PE头 |
在二进制文件中验证,其为倒数第二个变量且大小为2字节,所以在二进制文件中就是 ”E0 00“ ,由于是小端存储,所以对应大小就是224大小。
其在二进制文件中的位置为
1.4.3 节表

由结构体 IMAGE_SECTION_HEADER 构成,其大小为40个字节
1 | typedef struct _IMAGE_SECTION_HEADER { |
该部分可由多个节表组成,而这部分有多少个节表,后面的 节数据 就有多少钟
比对二进制文件
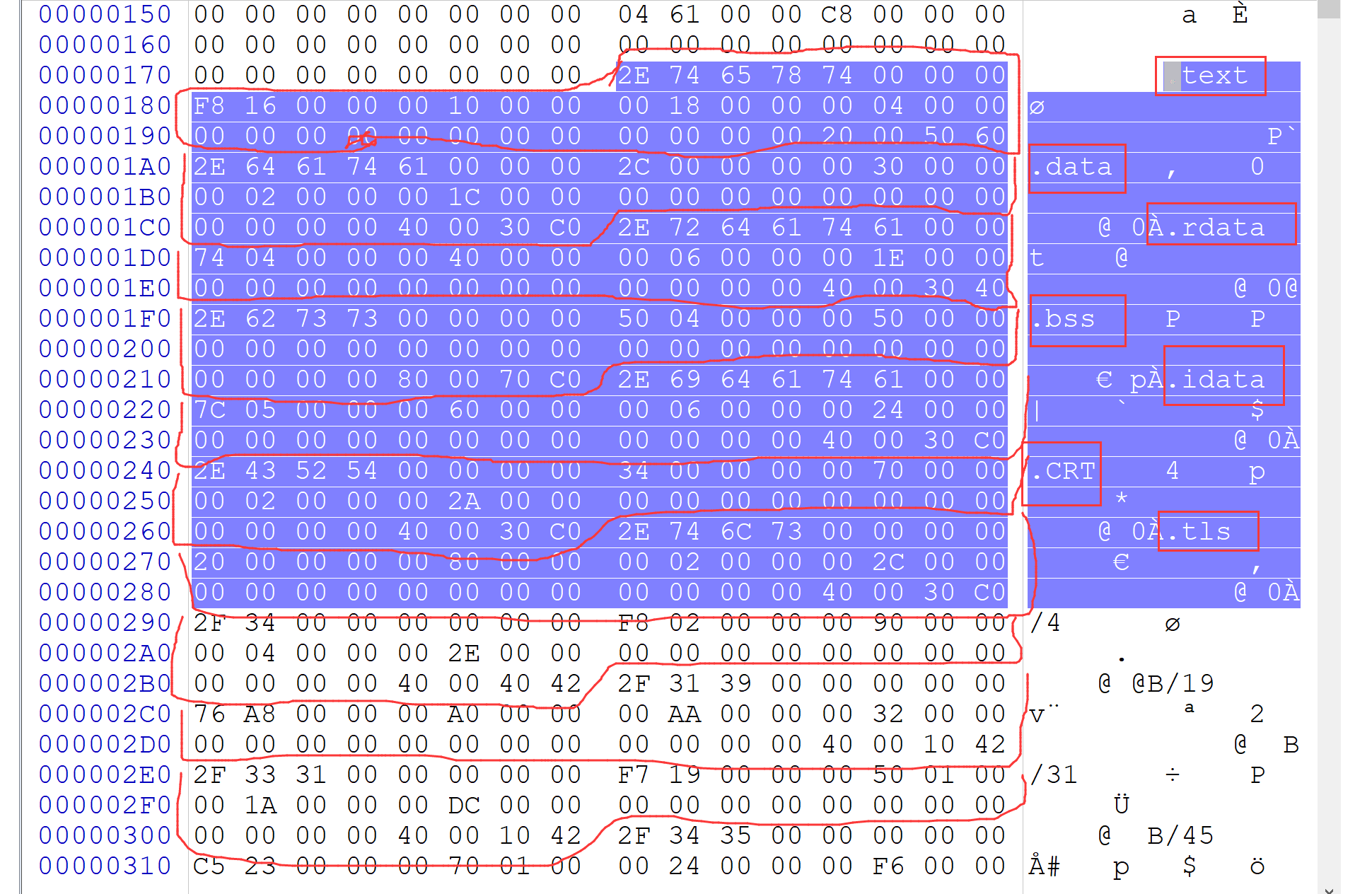
这个二进制文件有5个节表,每个节表都有ascii值所对应。
这部分后面就是由编译器放置的各种数据,而这部分后面才又是节数据。
而这部分长度又是怎么判断的呢?? 可以根据 拓展PE文件头 中的变量 SizeOfHeaders 来确定
1.4.4 节数据
首先要要找到它的位置,其判断方法就是:看 SizeOfHeaders 是多少,而 SizeOfHeaders 的大小就是
DOS头的大小 + PE头的大小 + 所有节表的大小 的结果再根据FileAlignment取其整数倍
1 | //扩展PE头 |
在二进制文件中验证:

其FileAlignment大小为”02 00“,SizeOfHeaders大小为”04 00“,符合其整数倍原则,所以,节数据的位置就可以从开始找400个字节,也可以直接看偏移量,如下就是节数据的内容
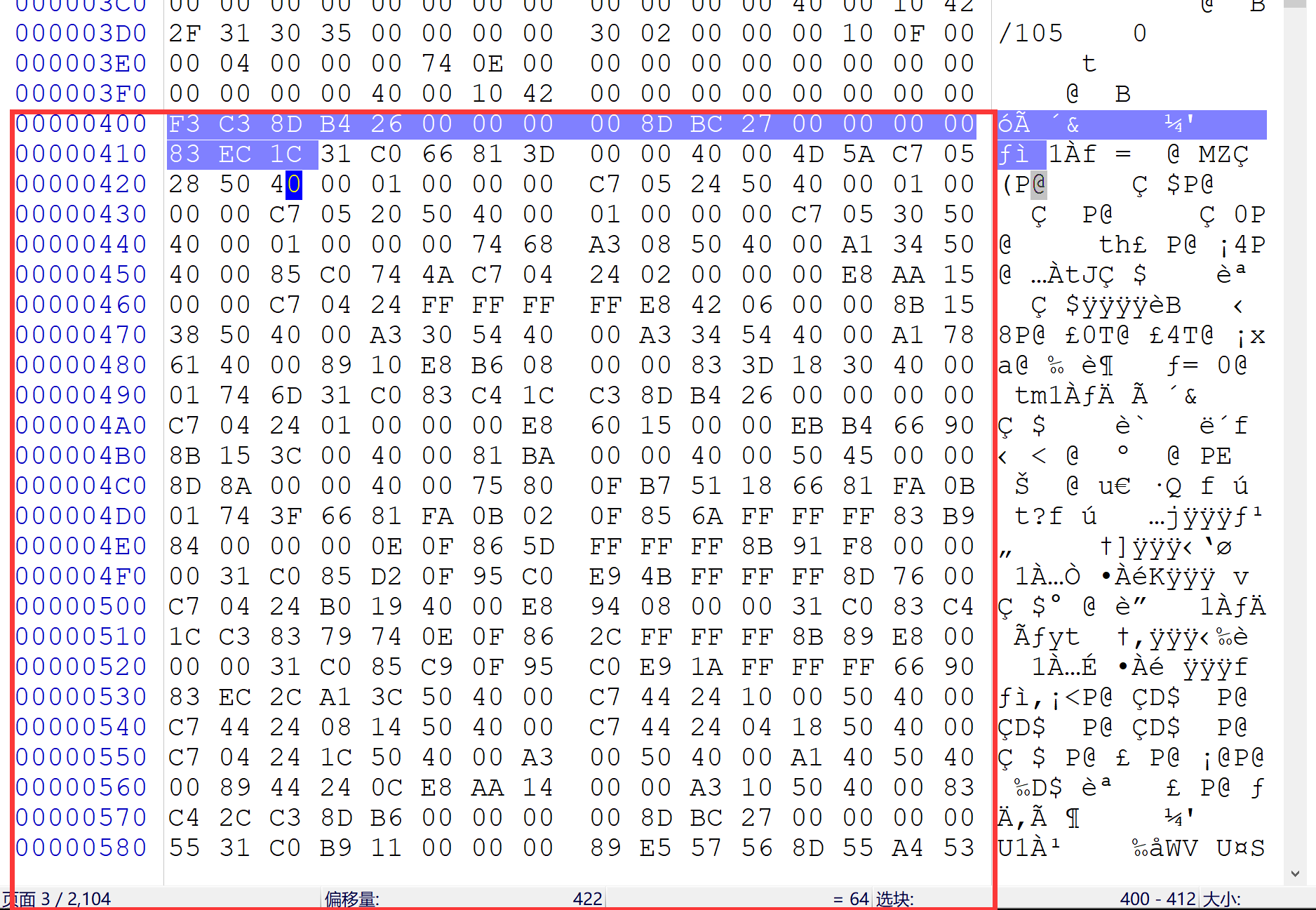
而节数据中的各个节块的大小也满足文件对齐的整数倍的原则
==注:PE文件在运行时,其状态和其在磁盘存储中时的状态有所不同。主要区分在文件对齐位的大小,还有总大小不同==
2.头文件的属性说明
2.1 DOS头
关于DOS头部分主要是因为最初的WINDOWS系统是在DOS下运行的,而存在一部分结构,而现在的windows平台大多数不需要,所以这部分结构中的内容,很大一部分已经被抛弃,现在也只需要两部分——就是”MZ”头部和指向PE头标识的尾部,所以其余部分都可以由我们随意更改包括藏病毒,藏flag之类的,也并不会对程序的运行造成任何阻碍。
2.2 PE头
1 | typedef struct _IMAGE_NT_HEADERS { |
2.2.1 标准PE头
1 | typedef struct _IMAGE_FILE_HEADER { |
文件属性 Characteristics 表
| 数据位 | 为1时的含义 |
|---|---|
| 0 | 文件中不存在重定位信息 |
| 1 | 文件是可执行的 |
| 2 | 不存在行信息 |
| 3 | 不存在符号信息 |
| 4 | 调整工作集 |
| 5 | 应用程序可处理大于2GB的地址(64位文件 |
| 6 | 此标志保留 |
| 7 | 小尾方式 |
| 8 | 只在32位平台上运行 |
| 9 | 不包含调试信息 |
| 10 | 不能从可移动盘运行 |
| 11 | 不能从网络运行 |
| 12 | 系统文件(如驱动程序),不能直接运行 |
| 13 | 这是一个DLL文件 |
| 14 | 文件不能在多处理器计算机上运行 |
| 15 | 大尾方式 |
2.2.2 扩展PE头
1 | 首先根据平台的不同32位和64位,其结构体成员有细微的差别,先把32位的看懂,64位也就能自行理解 |
1 | typedef struct _IMAGE_OPTIONAL_HEADER { |
文件特性–DllCharacteristics
| 数据位 | 相关特性 |
|---|---|
| 0 | 保留,必须为零 |
| 1 | 保留,必须为零 |
| 2 | 保留,必须为零 |
| 3 | 保留,必须为零 |
| 4 | DLL 可在加载时被重定位 |
| 5 | 强制代码实施完整性 |
| 6 | 该映像兼容DEP |
| 7 | 可以隔离,但并不隔离此映像 |
| 8 | 映像不使用SEH |
| 9 | 不绑定映像 |
| 10 | 保留,必须为零 |
| 11 | 该映像为一个WDM driver |
| 14 | 保留,必须为零 |
| 15 | 可用于终端服务器 |
==后续PE文件重点学习的就是:表,即扩张PE中最后两个成员的相关属性==
1 | DWORD NumberOfRvaAndSizes; |
3. 节表属性
首先要知道,在一个PE文件中节表是一个结构体数组,也就是有多个节表构成,同时,这部分数据按文件对齐的大小存储。可以通过FileAlignment看。
且该结构体中的成员大多都是标识 节数据 中的相关属性,包括在文件和在内存中的起始地址、在文件中尺寸
每个节40个字节大小
结构体**_IMAGE_SECTION_HEADER**
1 |
|
1 | 关于Misc和SizeOfRawData的大小关系: |
4.RVA和FOA的转换
首先要知道RVA和FOA是什么。
1 | RVA是相对偏移地址,就是一个全局变量在内存中的偏移地址。 |
然后我们可以通过这两个东西得到什么
实验:
1 | address:403004 |
1 | 假如我们得知了一个全局变量的在内存运行时的地址 |
结果:
1 | address:403004 |
可以看到全局变量的值被我们所修改,也就是说我们可以通过计算得到FOA的值,进而在2进制文件中修改全局变量的值,来达到和CE一样的效果。
5.在PE文件中添加代码
我们已经知道了,在一个PE文件中,可以通过它的2进制文件的一些空白区域进行填充代码,从而达到修改这个PE文件的执行结果的目的,但是,如果是两三句代码还好,一旦想填充的代码过多,就会造成修改到其他的源码的后果,所以这里就可以通过 扩大节 和 新增节 的技术,来进一步增加填充的区域。
6.扩大节
而想实现扩大节这一效果,步骤如下:
1 | 这里我们只需要修改想扩大的节的节表结构体中的成员,同时对修改到的关联的头部成员进行修改就行 |
1 | 我们需要修改的成员: |
具体步骤:
1 | [1]分配一块新空间,大小为--s |
实际操作–实验2
[1]-分配一块新空间,大小为 – 4096(0x1000)个字节
1 | 选中文件末尾,点击工具栏中 编辑-粘贴0字节-填入”4096“字节 |
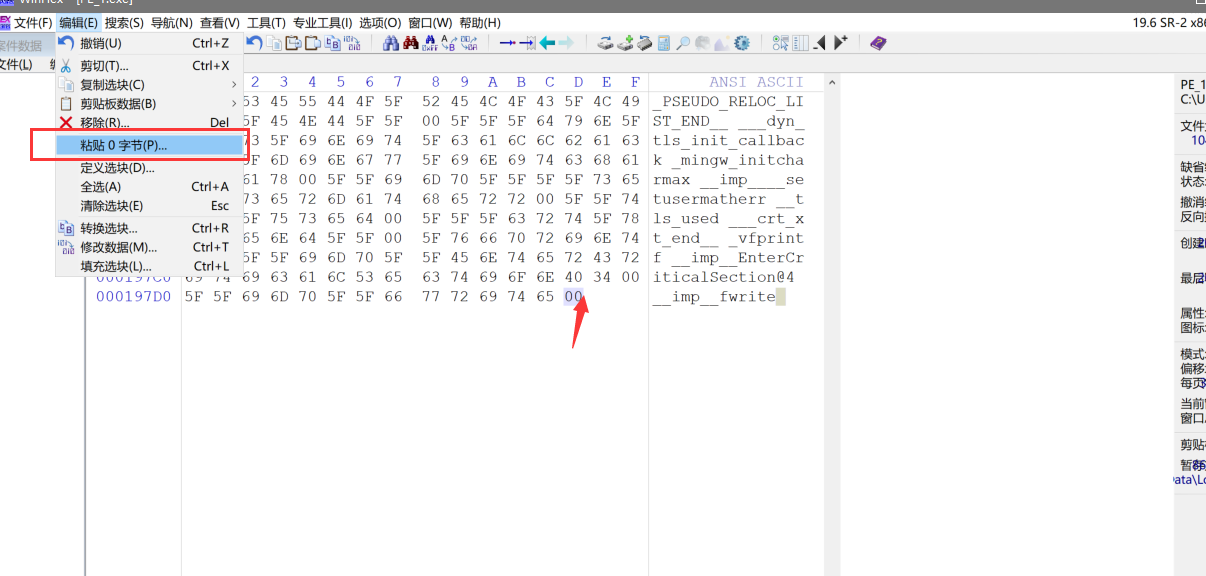

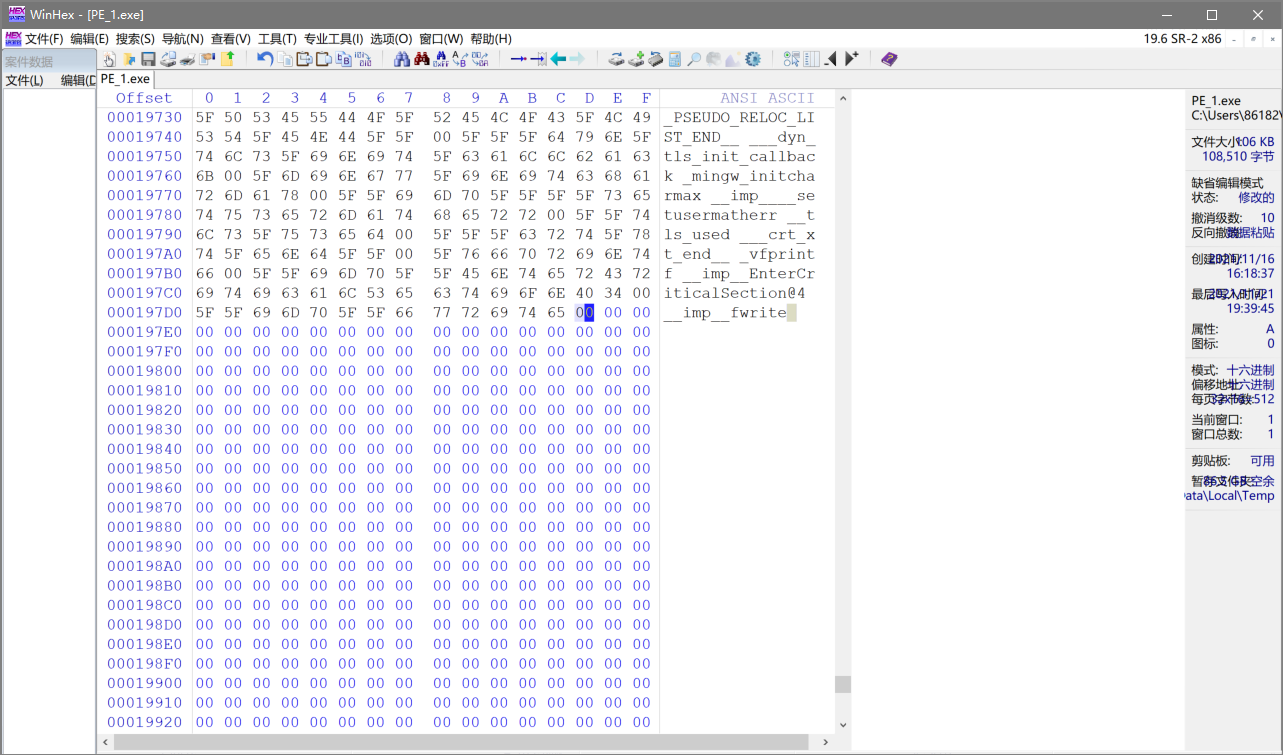
[2].将最后一个节的SizeOfRawData和VirualSize改成N
N = (SizeOfRawData或VirtualSize内存对齐后的值)+ s
1 | 这里选取的最后一个节表为---.tls |

[3].修改SizeOfImage的大小
==待定==
7.新增节
前面学习了扩大填充代码区域的技术之一扩大节,然后就是另外一个技术——新增节,在我们需要填充大量代码时,不必要将这部分代码拆分成多块,穿插在多个节与节之间空白区。可以直接新增节实现。
具体步骤:
1 | <1>判断是否有足够的空间,可以添加代码 |
具体实践:实验3
8.合并节
一丶简介
根据上一讲.我们为PE新增了一个节. 并且属性了各个成员中的相互配合. 例如文件头记录节个数.我们新增节就要修改这个个数.
那么现在我们要合并一个节.以上一讲我们例子讲解.
以前我们讲过PE扩大一个节怎么做. 合并节跟扩大节类似. 只不过一个是扩大. 一个是合并了.
合并节的步骤.
1.修改文件头节表个数
2.修改节表中的属性
节.sIzeofRawData 节数据对齐后的大小.
3.修改扩展头中PE镜像大小 SizeofImage
4.被合并的节以0填充.
二丶实战合并一个节
**1.**修改文件头中节表个数
为什么修改应该不用多说了. 我们既然合并. 那么节就要少一个.那么自然就进行修改了.

原节表有8个.我们修改为7即可.
2.修改节.SizeofRawData 节数据对齐后的大小.

我们把最后的AAAA节.合并到上一个节.rsrc中.
.rsrc.SizeofRawData = .文件对齐(rsrc.SizeofRawData + AAA.节数据的大小)
修改这个属性就按照上面的公式修改就行.原来节数据大小.加上要被合并的节的数据大小.按照文件对齐存放即可.
例如下图:

原来节数据对齐后的大小是0x600. AAAA节数据对齐后的大小是0x1000.那么修改.rsrc.SizeofRawData 为 0x1600即可.

最后一个节表以0填充即可.
**3.**修改扩展头的PE镜像大小 SizeofImage
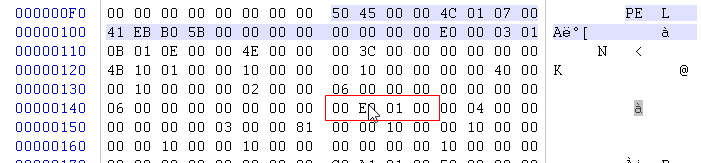
我们上一讲新增了一个节.所以映像大小为0x1E000. 所以现在要进行修改.合并了0x1000数据大小.那么改为0x1D000即可.
**4.**测试程序
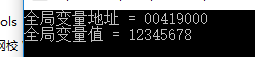
程序可以直接运行.那么内存中看看节展开位置有没有我们的合并节的节数据.

内存中0x41c000位置.就是节展开位置.我们没有合并之前.并没有我们的FFFF填充的数据.合并之后.出现了数据.说明已经成功合并了这个节了.
也相当于对这个节进行扩大了.
9.导入表与导出表
==注:学习这部分知识前,推荐先学习DLL文件的相关知识==
学习之前的知识,一个可执行程序被拖进winHex分析时,由一堆的二进制构成,这就是一个PE文件。但是一个可执行程序就是这么一个PE文件吗?并不是,当我们将一个可执行程序用OD分析时,在 “E”模块(当前程序的进程) 可以看到有许多的文件组成,这些都是标准的PE文件,包括DLL(动态链接库),为这个可执行程序提供函数或者其他功能。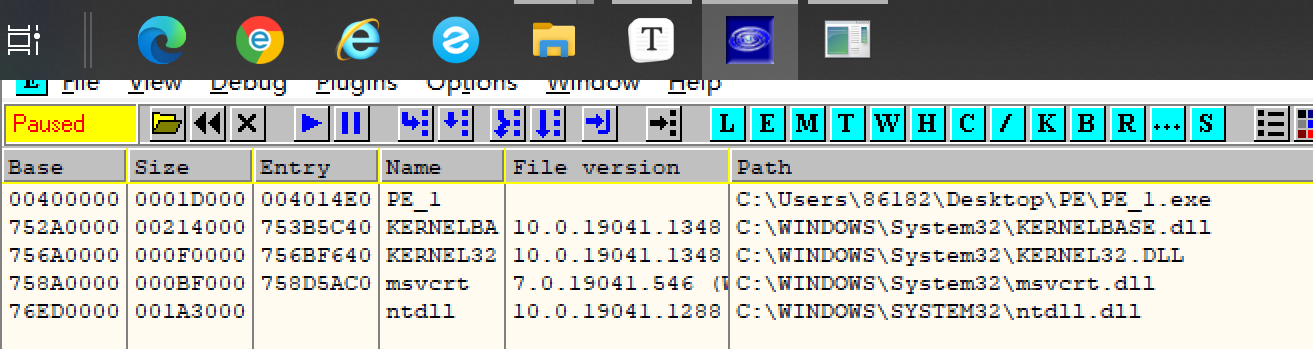
所以一个可执行程序通常是由多个PE文件构成,而看一个这个可执行程序使用到哪些PE文件(或由哪些PE文件构成)时,就可以去查看导入表获得这些信息。
而一个PE文件提供了那些函数,这些函数怎么用,等等相关信息,同样可以查表—-导出表
也就是说,一个可执行程序有一组PE文件构成,而这些PE文件通过导入表和导出表 进行联系。同时注意,一般exe文件由于很少提供函数,所以很少存在导出表,但是并不是不能有,从根本来看,他们都是PE文件,是相同的结构,所以是可以存在的。
怎样去查看这两张表呢?
首先认识他们
这两张表都在拓展PE头的最后一个属性—结构体数组IMAGE_DATA_DIRECTORY_ARRAY DataDirArray的中,由于是结构体数组,其结构都一样,每个结构体占8个字节,共16个结构体。
1 | IMAGE_DIRECTORY_ENTRY_EXPORT |
这就是指向导出表的结构体,位于结构体数组的第一个成员
1 | IMAGE_DIRECTORY_ENTRY_IMPORT |
这是指向导入表的结构体,位于结构体数组的第二个成员
9.1认识导出表
==注:图片中的DLL文件的文件对齐和内存对齐相同
1 | IMAGE_DIRECTORY_ENTRY_EXPORT |

1 | DWORD VirtualAddress----0x5A90 |
可以看到
导入表结构体:
1 | typedef struct _IMAGE_EXPORT_DIRECTORY { |
总共40个字节
前三个不是很重要,其中第二个成员TimeDateStamp–时间戳,和标准PE头中的时间戳一样,显示的是该DLL或EXE文件的生成的时间。
1 | DWORD Characteristics; |
重要的是后边几个成员,都是4字节的
1 | DWORD Name; |
除Base、NumberOfFunctions、NumberOfNames 存放的都是RVA内存偏移地址,要在文件状态查看的话需要转化为FOA,来找到它指向的值。

【图一】
一个一个来看
9.1.1 Name
在该部分的第12个字节后面的那四个地址0x5ADE

指向的字符串为DllDemo.dll这个就是这个DLL文件的名字。
==这里先跳过Base成员==
9.1.2 NumberOfFunctions 函数个数
指向该DLL文件所导出函数的个数,看【图一】,所指向的值为0x5,也就是说该DLL文件共导出5个函数,但是该文件实际编写中的只导出了4个函数
| EXPORTS | 函数序号 | 是否有函数名 |
|---|---|---|
| Plus | @12 | 有 |
| Sub | @15 | 无 |
| Mul | @13 | 有 |
| Div | @16 | 有 |
之所以显示的是0x5,是因为它的算法就是
1 | NumberOfFunctions = 函数序号最大值 - 函数序号最小值 |
9.1.3 NumberOfNames 以函数名称导出的函数个数
指向该DLL文件 以函数名称导出的函数个数 ,看【图一】,所指向的值为0x3,即有3个函数是以名字导出的。
9.1.4 AddressOfFunctions 导出函数地址表
指向了该DLL文件的函数地址表的RVA,看【图一】,其值为 0x5AB8,因为该DLL文件的内存对齐和文件对齐相同,即FOA=RVA,所以直接找到偏移量为0x5AB8进行查看

| 下标 | 函数地址表 |
|---|---|
| 0 | 0x00 00 10 10 |
| 1 | 0x00 00 10 30 |
| 2 | 0x00 00 00 00 |
| 3 | 0x00 00 10 20 |
| 4 | 0x00 00 10 40 |
可以看到中间有一个是0x00000000的地址,是一个空地址,也就是“有一个函数不存在”对应了导出的只有4个函数,但是 NumberOfFunctions 的值是5.
1 | 拓展知识: |
9.1.5AddressOfNames 导出函数名称表
该成员指向的地址同样也是RVA,在这个DLL文件中的他的FOA=RVA.还是看【图一】,值为0x5ACC

| 下标 | 函数名称表 | 指向字符串 |
|---|---|---|
| 0 | 0x00 00 5A EA | Div |
| 1 | 0x00 00 5A EE | Mul |
| 2 | 0x00 00 5A F2 | Puls |
可以看到其按开头字母的大小顺序存储。
9.1.6 AddressOfNameOrdinals 导出函数序号表
值得注意的是,函数名称表多大,序号表就有多大,在该PE文件中序号表存3个值,还是看【图一】
其RVA值为0x5AD8,由于FOA=RVA,所以FOA也等于0x5AD8

| 下标 | 函数序号表(两字节) |
|---|---|
| 0 | 0x00 04(4) |
| 1 | 0x00 01(1) |
| 2 | 0x00 00(0) |
认识完导出函数的各个表后,如何去查找这些函数呢?
windowsAPI提供一个函数
1 | FARPROC GetProcAddress( |
通过函数名去调用的话,像调用Div,首先在导出函数名表查找Div,然后根据其下标,(Div的下标为0)去导出函数序号表中根据下标进行查找对应的值(对应的值为4),将这个值定为导出函数地址表的下标,按对应的地址(0x00 00 10 40)找,就是该函数了。
还有一个方法通过函数序号去找的话,这个时候就要用到成员 Base
9.1.7 Base 导出函数起始序号
该成员指向的是,本文件的导出函数的起始序号,在该文件中的值为0x0C,就是12,最后完善导出函数地址表
| 下标 | 函数地址表 | 函数序号 |
|---|---|---|
| 0 | 0x00 00 10 10 | 12 |
| 1 | 0x00 00 10 30 | 13 |
| 2 | 0x00 00 00 00 | 14 |
| 3 | 0x00 00 10 20 | 15 |
| 4 | 0x00 00 10 40 | 16 |
最后假如查找的函数序号为**@15,这样就是直接找到地址0x00 00 10 20**的函数
9.2认识导入表
1 | 首先要知道一个进程是由一组PE文件构成的: |
指向导入表在哪里和导入表多大的是第二的结构体。
1 | IMAGE_DIRECTORY_ENTRY_IMPORT |

1 | DWORD VirtualAddress; |
这里用的EXE文件内存对齐和文件对齐一致,所以RVA=FOA。
由于一个模块对应一个导入表,所以一个PE文件里可能有多个导入表。
还是先认识导入表的基本结构体,一个导入表的宽度为20个字节
1 | typedef struct _IMAGE_IMPORT_DESCRIPTOR { |
9.2.1 确认导入表的数量
在全部的导入表结束后,会以20个连续的00结尾

按照其字节数,对这个文件进行划分,最后以20个连续的00结尾,可以看到这个PE文件由12个导入表组成
怎样判断是否就是12个导入表呢?
1 | 通过DTdebug打开该文件,并查看,就可以看到这个PE文件所有使用到的DLL文件 |
9.2.2 确认导入表的功能模块对应的DLL文件
导入表的看倒数第二个成员Name,
按照它的RVA转化为FOA找到偏移量对应的字符串

可以知道,这个PE文件的第一个导入表所依赖的DLL文件是KERNEL32.dll
9.2.3 通过导入表确定依赖的函数
这里就要看其他的导入表的其他两个成员OriginalFirstThunk、FirstThunk
1 | typedef struct _IMAGE_IMPORT_DESCRIPTOR { |
这两个成员各指向的一张表,但这两张表的结构相同,其结构体为
1 | typedef struct _IMAGE_THUNK_DATA32 { |
1 | typedef struct _IMAGE_IMPORT_BY_NAME { |
先来看OriginalFirstThunk指向的INT表,该表存储的就是导入函数名称,但是有两种情况
1 | 第一种: |
9.2.4通过导入表确定导入函数的地址
这里我们是通过IAT表来看的,也就是导入表的最后一个成员FirstThunk。
注意,IAT表有两种状态,根据PE文件的状态来看,也就是文件中和内存中的状态。
1 | 在文件中, |
1 | 补充知识: |
10.重定位表
想要认识重定位表,就要先要有这么一个概念:
1 | 一个进程由一堆PE文件构成,包括EXE、DLL,一个进程的运行依赖于这些个PE文件提供各种功能模块。 |
通过DTDUG调试展示:
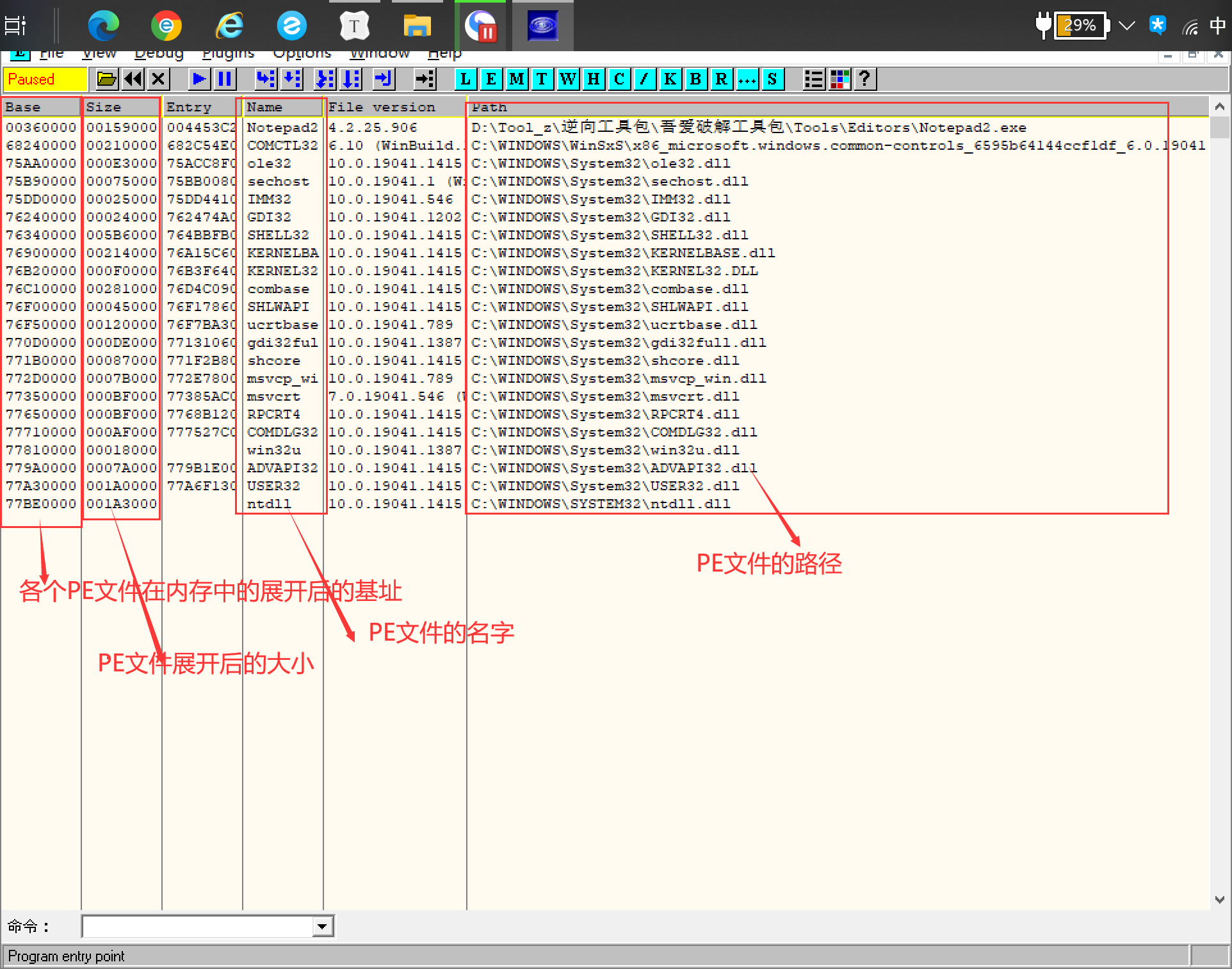
1 | 1.而这个进程中的很多的PE文件的ImageBase是相同的,这就需要操作系统进行更改,这是一部分 |
1 | 也就是说 |
10.1如何找到重定位表
和导入表和导出表一样,在扩展PE头的最后一个结构体成员去找,找到第6张表,这张表就是存储重定位表的地址和大小的表。
结构如下:
1 | typedef struct _IMAGE_BASE_RELOCATION { |
要注意的是,重定位表并不只有一块,因为,每个PE文件中,有 地址冲突 的不止一个数据,所以他就存在多个重定位块。如何去判断重定位表的结束呢?
这里就要介绍**_IMAGE_BASE_RELOCATION**这个结构体中的两个成员了
首先是virtualAddress,就是一个重定位表的基址,即需要修改的数据的地址的一个基址,实际地址是这个基址加上SizeOfBlock后边的两个字节,两个字节的加(virtualAddress+两字节)。
然后是SizeOfBlock,表示这张重定位表的大小,即可通过这个值判断重定位表的边界。
结束的标志 就是:当SizeOfBlock和virtualAddress都为0时,重定位表块也就结束了。
10.2重定位表的重定位操作
之前提到了重定位表中的两个成员,SizeOfBlock和virtualAddress,假设他们现在的存储就是下图
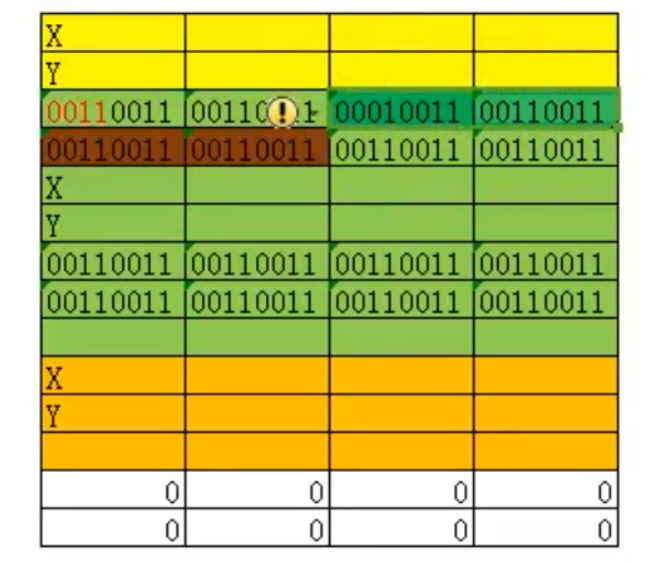
X代表的就是中存储的virtualAddress,Y代表的就是SizeOfBlock,一个就是1个字节,现在找到第一张表,其要修改的值就是 X的值 + 后面两字节的值,然后这里要注意,这两个字节的高4位
1 | 高位前4位无效 只需要12位 |
在对重定位表进行修改的时候,就需要判断该地址(高四位是否为3)指向的数据是否需要修改
本次初学PE的笔记到此结束!后序还PE文件的一些实验将更新。。。